

В последние несколько лет большое внимание уделяется исследованию вопросов распознавания различных объектов, в частности, текстовых документов, с использованием мобильных телефонов, как в качестве устройств захвата изображения, так и в качестве вычислительных устройств. Так, в разных работах обычно подходят к рассмотрению каких-то подзадач, например, таких, как оценка качества изображений, отдельные задачи распознавания, постобработка полученных результатов. При этом серьезному рассмотрению процесса в целом, а особенно возникающим обратным связям уделяется значительно меньше внимания. В основном рассматриваются системы, в которых захват кадра производится мобильным телефоном, а распознавание выполняется на сервере. В данной работе мы рассматриваем схему построения системы распознавания на устройстве, возникающие обратные связи и их применение для повышения качества распознавания.
Рассматривается задача распознавания документов на примере паспорта гражданина РФ с помощью мобильного устройства. Исходными данными служит видеопоток (набор кадров), полученный камерой мобильного устройства. В отличие от сканера, документ может располагаться в некоторой произвольной плоскости относительно плоскости сфокусированного изображения, что добавляет задачу проективного преобразования полученных кадров. Задача распознавания документа, как правило, разделяется на следующие этапы:
– детектирование документа в кадре;
– нахождение зоны и параметров проективного восстановления;
– проективное исправление изображения документа;
– позиционирование зон реквизитов (полей) на исправленном изображении;
– распознавание реквизитов;
– постобработка.
В случае видеопотока задача постобработки является особенно актуальной. Межкадровая информация позволяет повысить точность и скорость получения результата распознавания [2]. Мы остановимся на решении задачи интеграции результатов распознавания отдельных полей и на организации управления механизмом распознавания с целью оптимизации быстродействия.
Описание алгоритма
Пусть для каждого отдельно взятого документа есть набор из n распознанных кадров I0, I1,…, In-1 соответственно с m распознанными полями F0(Ii), F1(Ii), …, Fm-1(Ii). Для простоты будем рассматривать последовательность результатов для одного конкретно взятого поля. Каждое поле представимо в виде набора знакомест:
A(Ii)={A1(Ii), … Al(Ii)},
где l=l(Ii) – количество распознанных знакомест в поле (это количество зависит от кадра и равно 0, если поле не распознано вовсе), а каждое знакоместо Aq(Ii) содержит код символа sq(Ii) и его оценку wq(Ii) в диапазоне 0÷1. Значения 1–wq(Ii) будем интерпретировать как вероятности ошибочного распознавания знакоместа Aq(Ii).
Пусть поле состоит из одного слова (например, фамилии). Тогда для поля, представимого в виде строки S(Ii) = {s1(Ii), … sl(Ii)} и оценок {w1(Ii), … wl(Ii)}, определим оценку всего поля:
Θ(S(Ii)) = 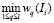 . (1)
. (1)
Пусть имеется последовательность распознанных слов с оценками
{(S(I1), Θ(S(I1))), …, (S(Ik), Θ(S(Ik)))}.
Необходимо определить наилучший результат распознавания по нескольким первым словам, минимизируя число выбранных слов. Для этого объединим одинаковые строки в популяции для организации отбора и ранжирования популяций [3–5]. Каждая популяция Pp состоит из слова S(Pp), оценок знакомест {w1(Pp), … wl(Pp)}, количества строк |Pp|, попавших в популяцию, и оценки популяции Θ(Pp).
При первом обнаружении поля создается популяция из одного слова с оценкой, равной оценке этого слова. При дальнейшем добавлении строки S(Ii) оценка wq(Pp) знакоместа Aq вычисляется следующим образом:
1– (1– wq(Pp)) (1 – w′q(Ii)),
где w′q(Ii) – оценка добавляемой строки, а wq(Pp) – оценка знакоместа популяции. После очередного шага t происходит оценка состояния популяций путем сравнения каждого с заранее заданными оценками. При нахождении хотя бы одной популяции, удовлетворяющей условиям, процедура рассмотрения новых строк прекращается, и в качестве наилучшего результата берется эта самая популяция. В случае наличия некольких таких популяций, берется популяция с наилучшей оценкой.
Подход может быть усовершенствован, если оценка поля вычисляется следующим образом:
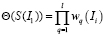 ; (2)
; (2)
или по формуле
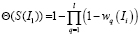 . (3)
. (3)
Для полей, состоящих из нескольких слов (например, место рождения), предлагается сделать разбиение на отдельные слова с последующей конкатенацией выбранных «наилучших» вариантов слов в качестве результата.
Данный алгоритм был проверен на некотором тестовом наборе данных с хорошим и средним качеством видеосъемки паспортов РФ, т.е. видеопоследовательности могли иметь незначительные дефекты (блики, смазывания, дефокусировка) [1]. Набор состоял из 67 видеопоследовательностей объемом от 17 до 100 кадров. Анализировалось распознавание семи полей (ФИО, номер и серия паспорта, дата и место рождения), одно поле (место рождения) состояло из нескольких слов, остальные поля – из одного слова.
Для оценки предложенного алгоритма интеграции использовались две характеристики:
– точность, определяемая как доля результатов распознавания, совпадающих с истинным значением поля,
– ускорение, определяемое как среднее значение количества слов, необходимых для интеграции, отнесенного к количеству кадров видеопоследовательности.
Характеристики алгоритма, полученные на данном наборе, сведены в табл. 1–3.
Таблица 1
Характеристики алгоритма с использованием формулы (1)
|
Поле |
Точность |
Ускорение |
Среднее число кадров |
|
Фамилия |
0,99 |
0,14 |
5,47 |
|
Имя |
0,99 |
0,1 |
4,59 |
|
Отчество |
0,99 |
0,11 |
4,91 |
|
Серия паспорта |
0,97 |
0,08 |
3,78 |
|
Номер паспорта |
0,99 |
0,08 |
3,68 |
|
Дата рождения |
0,96 |
0,08 |
4,34 |
|
Место рождения |
0,91 |
0,22 |
8,87 |
Таблица 2
Характеристики алгоритма с использованием формулы (2)
|
Поле |
Точность |
Ускорение |
Среднее число кадров |
|
Фамилия |
0,93 |
0,18 |
8,66 |
|
Имя |
0,99 |
0,1 |
4,62 |
|
Отчество |
0,99 |
0,11 |
5,16 |
|
Серия паспорта |
0,97 |
0,08 |
3,72 |
|
Номер паспорта |
0,99 |
0,08 |
3,72 |
|
Дата рождения |
0,96 |
0,08 |
3,31 |
|
Место рождения |
0,84 |
0,23 |
8,12 |
Таблица 3
Характеристики алгоритма с использованием формулы (3)
|
Поле |
Точность |
Ускорение |
Среднее число кадров |
|
Фамилия |
0,97 |
0,16 |
7,34 |
|
Имя |
1 |
0,12 |
5,47 |
|
Отчество |
1 |
0,11 |
5,34 |
|
Серия паспорта |
0,97 |
0,13 |
5,84 |
|
Номер паспорта |
0,91 |
0,08 |
4,09 |
|
Дата рождения |
0,97 |
0,08 |
3,16 |
|
Место рождения |
0,85 |
0,24 |
9,41 |
Заключение
Отметим, что в основном ошибки алгоритма интеграции объясняются случаями отсутствия правильных результатов распознавания, а также ошибками поиска границ поля. Также отметим, что, несмотря на низкие средние значения ускорения, реальные значения r/(z2–z1), для некоторых видеопоследовательностей точность близка к 1.
Что касается среднего числа кадров, необходимого для распознавания, то для поля «место рождения» получаем, что в среднем достаточно 8–9 кадров, для остальных полей – 3–5. Поле «место рождения», как правило, состоит из нескольких слов, и для каждого из них происходит выбор наилучшего. Поэтому полученное для него значение объясняется тем, что при отборе каждого слова число кадров, необходимое для распознавания и достижения при этом заданного уровня точности, может быть различным, и, следовательно, нужно взять наибольшее.
Таким образом, предложенный алгоритм интеграции позволяет получить высокую точность распознавания полей при существенном ограничении качества исходных данных для распознавания.
Работа была выполнена при поддержке РФФИ (проект № 16–29–09508).
Библиографическая ссылка
Булдакова Т.И., Славин О.А., Путинцев Д.Н. АЛГОРИТМЫ ИНТЕГРАЦИИ РЕЗУЛЬТАТОВ РАСПОЗНАВАНИЯ В ВИДЕОПОСЛЕДОВАТЕЛЬНОСТЯХ ПОЛЕЙ ДОКУМЕНТОВ, УДОСТОВЕРЯЮЩИХ ЛИЧНОСТЬ // Международный журнал прикладных и фундаментальных исследований. – 2017. – № 7-2. – С. 172-175;URL: https://applied-research.ru/ru/article/view?id=11714 (дата обращения: 18.04.2024).