

В связи со стремительным ростом разнообразной подводной техники, особенно самоходных и привязных беспилотных подводных аппаратов, стало реальностью решение задач навигации подводных аппаратов, в том числе с использованием средств технического зрения. Это стало возможным благодаря появлению высокопроизводительной компьютерной техники, позволяющей эффективно решать задачу выявления признаков объектов, достаточных для того, чтобы производить движение с заданным поведением относительно объектов и стабилизацией положения относительно окружающего пространства. При этом применяются алгоритмы, которые используются в искусственном интеллекте и интеллектуальном управлении в частности [1].
Целью исследования являлась разработка программно-аппаратной платформы интеллектуальной системы автоматического управления телеуправляемыми и автономными подводными аппаратами, обеспечивающая автоматическое перемещение ТНПА в толще воды с использованием особенностей окружающего рельефа и объектов, автоматическое перемещение в заданную точку, обнаружение и обход препятствий [2].
Для выполнения работы были созданы средства координации, обеспечивающие локальную стабилизацию аппарата под водой по курсу и глубине, локальное позиционирование, обнаружение и обход препятствий на основе технического зрения, а также стабилизацию относительно объектов.
Автономность перемещения до визуального контакта с поверхностью или объектом спереди осуществляется с использованием бортовой инерциальной системы. При обнаружении объекта производится автоматическое переключение на управление аппаратом с применением технического зрения. Подтверждение сближения осуществляется передним сонаром и альтиметром или эхолотом для измерения отстояния от дна и данных с датчика глубины. Стабилизация аппарата в пространстве достигается инерциальной, визуальной системами управления на основе данных с сонаров и датчика глубины, являющимися основными в режиме следования без визуального контакта с объектами [1].
Решение данных задач обеспечивает повышение качества и скорость выполнения подводно-технических работ, снижения зависимости подводного аппарата от внешних воздействий, человеческого фактора.
Помимо основных задач также решается задача картографирования и лоцирования дна, при этом осуществляется запись как потокового видео при автоматическом осмотре гидротехнических сооружений или коммуникаций, так и сохранение отдельных объектов, выявленных системой технического зрения, что дает возможность использования небольших накопителей [3]. Реализуется задача поиска затонувших объектов, долговременного мониторинга состояния потенциально опасных объектов, сопровождения подводно-технических работ (например, путем оценки изменения картины и показаний сенсоров в ходе их выполнения). Для выполнения физической реализации используется подводный модуль и непосредственно сама платформа, снабженная вспомогательными средствами береговой станции и пользовательского интерфейса с блоком управления.
В целом решается комплексная научно-техническая задача, направленная на разработку инновационных программных и аппаратных средств нового поколения, позволяющих обеспечить максимальную автоматизацию процессов управления подводными аппаратами при выполнении поисковых и подводно-технических работ, производить их улучшение за счет расширенных функций оператора, уменьшить сложность их контроля [4].
Далее была выбрана структурная схема интерфейсов платформы с гидроакустическими и инерциальными сенсорами. Разработаны алгоритмы обработки и интерпретации данных со связки гидроакустических и инерциальных приборов. Произведена интеграция сенсоров в информационно-управляющую система ТНПА.
В ходе решения были реализованы подсистемы телекоммуникаций, сбора и обработки данных, визуализации данных телеметрии на экране, интеллектуального управления на основе систем счисления пути. Реализованы функции, позволяющие производить независимую настройку отдельных компонент системы [2].
Разработаны алгоритмы полуавтоматического и автоматического движения на базе получаемых данных от системы счисления пути на основе датчиков акустической навигационной системы. Алгоритмы обеспечивают автономное движение ТНПА между заданными точками с автоматическим обходом препятствий [5]. Произведена разработка интерфейса между акустическими компонентами и платформой ТНПА в виде соответствующих наборов команд, а также пользовательский интерфейс.
Современные мобильные роботы с различной степенью автономности снабжаются компонентами управления, разрабатываемыми на основе алгоритмов глубокого обучения с подкреплением (ОП).
Принципиальными свойствами процедуры обучения являются:
− отложенное (разреженное) вознаграждение: сигнал обратной связи может характеризовать не каждое решение агента, но результат некоторой последовательности решений. В случае автономного перемещения ТНПА к заданной цели отложенное вознаграждение формируется в момент достижения цели, а его величина зависит от точности конечной позиции и от общего времени достижения цели;
− частично плотное вознаграждение: сигнал обратной связи может характеризовать как качество каждого отдельного решения, так и результат последовательности решений. В случае автономного перемещения ТНПА мерами качества отдельных решений служат оценка радиуса кривизны траектории (в подходе «чем больше – тем лучше»), дисперсия скорости ТНПА (в подходе «чем меньше – тем лучше») и другие характеристики;
− компромисс исследования и использования: агент должен принимать решения, приводящие как к повышению вероятности достижения цели (использование), так и к исследованию альтернативных решений, потенциально приводящих к достижению цели (исследование);
− среда, с которой взаимодействует агент, недетерминированная и стохастическая; на современном уровне развития технологий не подразумевается возможность построения агентом некоторой модели мира, позволяющей аппроксимировать поведение среды и, в соответствии с этим, принимать более оптимальные решения с точки зрения функционала вознаграждения.
Целью настоящего исследования является разработка обучаемого алгоритма-агента, управляющего решениями ТНПА по мере продвижения к цели, поставленной оператором, при условии восприятия окружающей водной среды, стационарных и движущихся препятствий и морского дна посредством оптических и гидроакустических сенсоров.
В настоящем исследовании была использована виртуальная окружающая среда с открытым исходным кодом DeepMindLab. ВОС DeepMindLab предоставляет возможность конструировать сложные задачи трехмерной навигации и решения головоломок. Эта ВОС реализует сценарий восприятия окружающей среды «от первого лица», что позволяет использовать ее для обучения агента ТНПА. В настоящем проекте используется возможность создания ВОС трехмерной навигации. Основная цель ВОС DeepMindLab –служить испытательной площадкой для исследований в области искусственного интеллекта, особенно глубокого обучения с подкреплением. ВОС DeepMindLab можно использовать для изучения того, как автономные искусственные агенты могут выполнять сложные задания в больших мирах, наблюдаемых лишь частично и характеризуемых существенным визуальным разнообразием. В настоящем проекте возможности ВОС DeepMindLab были адаптированы к задаче трехмерной навигации в вязкой среде с зашумлением сенсорных данных и дополнением источника сенсорных данных гидроакустического локатора. На рис. 1 приведена схема наблюдений, доступных агенту в ВОС DeepMindLab. Следует отметить, что в качестве RGBD данных, приведенных на рис. 1, моделируются как данные визуальных наблюдений, так и данные гидроакустического локатора. На рис. 2 приведена схема возможных решений, доступных для агента в ВОС DeepMindLab.
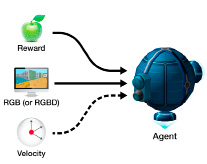
Рис. 1. Сенсорные данные и вознаграждение, доступные агенту в ВОС DeepMindLab [5]: Reward – вознаграждение; RGB – сенсорные данные с оптических камер ТНПА; RGBD – визуальные сенсорные данные с дополнительным каналом D, кодирующим дальность до препятствий; Velocity – скорость перемещения агента в среде
Материалы и методы исследования
Метод обучения агента управления ТНПА. Большинство существующих подходов ОП, реализующих автономную навигацию, относятся к одной из двух категорий: модульные конвейеры [5], которые создают исчерпывающую модель окружающей среды, и подходы имитационного обучения, которые сопоставляют сенсорные данные непосредственно с контрольными выходами. Недавно предложенная третья парадигма «прямого восприятия» (DP: direct perception) направлена на объединение преимуществ обоих типов методов с применением глубокой искусственной нейронной сети для извлечения подходящих низкоразмерных скрытых представлений. Существующие подходы DP обычно ограничиваются простыми ситуациями, в которых не предусматривается возможностей соблюдать ограничения скорости или максимальной кривизны траектории.
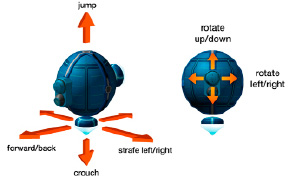
Рис. 2. Пространство действий (решений), предоставляемое ВОС DeepMindLab для агентов [5] Действия ограничены перемещениями в трех измерениях и поворотами вокруг двух осей для визуального и гидролокационного исследования окружающей среды
Метод, реализованный в настоящем проекте, использует подход прямого восприятия, который сопоставляет композитные сенсорные данные со скрытыми представлениями, подходящими для автономной навигации в сложных условиях вязкой оптически зашумленной среды.
Вместо аппроксимации подробно интерпретируемого представления окружающей среды цель DP состоит в том, чтобы вычислить низкоразмерно скрытое представление окружающей среды, которое затем используется в обычном алгоритме управления для маневрирования ТНПА. Таким образом, DP не требует от сети сквозного изучения сложной проблемы сенсомоторного управления и не предполагает наличия наборов визуальных данных с попиксельной или поблочной разметкой, получение которых требует значительного времени, особенно когда идет речь о разметке данных водной толщи.
В основе подхода DP лежит выбор прогнозируемого скрытого представления. В идеале это представление должно иметь низкую размерность, но при этом содержать всю необходимую информацию для принятия решения о маневрировании. Одним из вариантов такого представления являются атрибуты среды, которые ограничивают пространство разрешенных действий – так называемые аффордансы.
Прямое восприятие DP формулируется как многоцелевое обучение (Multi-tasklearning): используя одну нейронную сеть, мы прогнозируем все аффордансы за один заход вычислений нейросети. Это дает эффективное с вычислительной точки зрения решение – для прямого прохода система (сеть + контроллер) занимает в среднем 50 мс на графическом процессоре NVIDIA GTX 1080 Ti. Это вполне соответствует требованиям реального времени для автономных систем управления в трехмерной среде, где задержка не должна превышать уровня 300 мс. Кроме того, было показано, что в подходе MTL нейросеть тренируется извлекать скрытые представления, которые могут улучшить ее обобщающую способность. Например, в работе Xu et al. этот эффект был продемонстрирован на примере задачи автономного вождения. В нейросети, извлекающей низкоразмерное признаковое описание состояния среды, все сверточные слои используются для всех задач управления ТНПА. Этот подход широко применяется в MTL-задачах извлечения представлений данных. При этом решение для каждой задачи управления аппроксимируется в виде вероятностного выхода соответствующей полносвязной ветви нейросети: выходные данные последнего сверточного слоя используются в качестве входных данных для ветвей, специфичных для каждой из задач управления. В дальнейшем они будут называться «блоками задач».
В настоящем проекте для извлечения признаков применяется сверточная часть сети VGG-16, предварительно обученной на наборе визуальных данных ImageNet. Простая структура сети делает ее привлекательным выбором в качестве инструмента извлечения признаков при условии ограничений на время исполнения. Нейросеть VGG-16 вычисляется на каждом изображении во входной последовательности для извлечения последовательности карт активации. Блоки задач представляют собой неглубокие полносвязные сети и состоят из слоя, специфичного для конкретной задачи управления, за которым следует слой пакетной нормализации и слой прореживания Dropout. Для слоев, специфичных для конкретных задач, были проведены эксперименты на предмет качества аппроксимации верного решения. В частности, рассматривались варианты полносвязных слоев, рекуррентных ячеек LSTM, GRU и слоями ConvLSTM. Каждый блок задач имеет свое специфическое поле восприятия во времени и факторы временного прореживания (например, может использоваться каждое второе изображение видеопотока). Выходные нейроны блоков условных задач разделены на три группы одинакового размера. Например, команда направления С, принимающая одно значение из набора {прямо, влево, вправо} используется для переключения между этими группами элементов управления ТНПА. Следует учесть, что только активная группа используется для вычисления метки команды. При этом во время обучения нейросети агента градиенты функции потерь распространяются только в этой группе. Такой подход изолирующего обучения отдельных групп приводит к лучшей производительности по сравнению с использованием команды направления С в качестве дополнительного входа в сети задач.
Поскольку процедура обучения нейросети агента управления ТНПА в нашем подходе вычисление аффордансов и команд управления разделены, можно обучать стек DP независимо от выбранного алгоритма управления. Для обучения сети аппроксимации афордансов были смоделированы два набора данных с помощью ВОС DeepMindLab: Среда 1 – для обучения и Среда 2 – для оценки качества достижения цели (автономное перемещение из точки А в точку Б). Для сбора данных для обучения агента в Среде 1 тестовый агент перемещался по этой среде с максимально возможными вариациями направлений, скоростей и углов поворота, однако с учетом реальных возможностей ТНПА. Во время сбора данных в Среде 1 направление поворотов, время принятия решения о поворотах и прочие параметры изменения траектории сэмплировались произвольно из стандартного нормального распределения с масштабными коэффициентами, удовлетворяющими физическим возможностям ТНПА и ограничениям на минимальный радиус кривизны траектории и максимальную дисперсию скоростей ТНПА [6]. Все остальные агенты (неуправляемые движущиеся и стационарные препятствия) контролировались ИИ, симулируемым ВОС DeepMindLab. Полный набор данных содержит приблизительно 370 тыс. изображений и сканов сонара, а также соответствующих истинных значений для каждого из четырех аффордансов. Для оценки качества функционирования обучаемого агента использовалась подвыборка данных, составляющая 10 % сгенерированного набора Среды 1. Нейросеть аппроксимации аффордансов и команд управления обучалась на мини-батчах размером 32 изображения (и соответствующих сканов сонара).
Как и в любой задаче с применением глубоких искусственных нейронных сетей, в этой задаче необходимо применять искусственное дополнение данных (аугментацию). Следуя сложившимся в области автономной навигации практикам, были применены следующие аугментации: изменения цветового баланса, контраста и яркости оптического изображения; гауссовое размытие; дополнительное зашумление черными и белыми дефектами небольших размеров (аугментации типа «соль» и «перец»). В дополнение к упомянутым аугментациям применялось зашумление позиции камеры и сонара, а также зашумление направлений обзора камеры и сканирующего сонара с пределами случайного поворота в 15 градусов. Эти аугментации применялись, поскольку известно, что в задачах имитационного ОП фиксирование направления обзора камеры приводит к снижению обобщающей способности агента и ошибкам в командах контроля. В 10 % случаев в дополнение к упомянутым аугментациям применялась специфичная для задачи аугментация, заключающаяся в генерации неожиданно возникающего препятствия на пути следования ТНПА. Эта аугментация применялась для обучения агента поведению экстренной остановки в соответствующей ситуации и передачи управления на оператора. Результаты обучения агента в рамках описанной процедуры приведены в таблице.
Следует отметить, что агент обучался только на данных Среды 1. Качество агента оценивалось как на данных Среды 1, так и на данных Среды 2 (не демонстрированных в процессе обучения). Показатели качества для Среды 2 приведены в третьей и четвертой колонках таблицы. Также следует отметить, что и для Среды 1 (тренировочной), и для Среды 2 (тестовой) варьировались показатели зашумления визуальной сцены, получаемой с видеокамеры, и показатели зашумления данных сканирующего сонара. Показатели качества в условиях модифицированного шумового фона приведены во второй и четвертой колонках таблицы.
Количественная оценка качества трехмерной навигации агента управления ТНПА в различных сценариях. Качество оценивается в мере успешно выполненных задач навигации из точки А в точку Б с заранее заданной точностью (отклонение от точки Б не более 5 % дистанции до судна сопровождения)
|
Тренировочные условия (Среда 1) |
Новые условия видимости |
Незнакомый рельеф и препятствия (Среда 2) |
Новые рельеф, препятствия и условия видимости |
|
|
Прямая траектория без препятствий |
100 % |
100 % |
93 % |
94 % |
|
Единственное явно различимое статическое препятствие |
97 % |
96 % |
82 % |
72 % |
|
Несколько явно различимых статических препятствий |
92 % |
90 % |
70 % |
68 % |
|
Несколько статических и динамических препятствий |
83 % |
82 % |
64 % |
64 % |
Заключение
Произведена разработка интерфейса между блоком управления ТНПА и платформой ТНПА в виде соответствующих команд, их обработчиков и условий для обработки, включая пользовательский интерфейс с расширенными функциями, необходимыми для выполнения автономных и полуавтоматических работ.
Произведено лабораторное испытание элементов платформы ТНПА на соответствие требуемым техническим характеристикам, а также внутренним испытаниям, подтверждающим их работоспособность. В частности, можно выделить следующие технические характеристики на математических моделях и физических экспериментах. Автономное перемещение в заданную точку с применением инерциальной системы счисления пути и сенсоров, расчет скорости перемещения подводного аппарата, движение по заданной траектории, сохранение изображений объектов и локальная картография дна, распознавание границ объектов, определение отстояния от дна и от поверхности, реализован пользовательский интерфейс с вводом соответствующих значений координат точек назначения, территории выполнения работ, режимов работ, привязки к объекту слежения, отображения трека, отображения локального рельефа, сохранения визуальных данных.
Институт океанологии является лидером разработок и использования малогабаритных телеуправляемых подводных аппаратов ГНОМ, следующее поколение которых будет оснащено искусственным интеллектом.